Netflix processes over 4.3 billion writes and 2.1 billion reads per day across more than 50 Cassandra clusters, demonstrating its capacity to handle massive data volumes with low latency.
Cassandra truly shines with its impressive read and write speeds. Its distributed architecture allows it to handle massive volumes of data with low latency, making both reads and writes incredibly fast and efficient. The ability to perform writes with minimal overhead ensures that high-throughput applications can rely on Cassandra without bottlenecks.
If you’re new to Cassandra, feel free to check out the earlier posts in this series to get up to speed on how it all works.
- Cassandra: Write Fast, Scale Forever
- Cassandra: Internals & Architecture
- Cassandra: Mighty Storage Engine
Additionally, its optimized read paths and tunable consistency levels allow for flexible performance trade offs that keep data access blazing fast. Overall, Cassandra’s speed in both reading and writing data makes it a top choice for real-time, large-scale applications.
Understanding Cassandra’s internal mechanisms for read and write operations reveals why it performs so well in large scale, distributed settings. We will break down the anatomy of Cassandra’s read and write paths, highlighting the steps involved and how it balances performance, consistency, and availability.
The Write Path in Action
The Write Path signifies efficiency, durability, and and fault-tolerant distribution.
Cassandra’s write path is designed for speed and resilience. It avoids blocking writes on slow disks while ensuring durability and replication guarantees.
When a client sends a write request, it can connect to any node in the cluster. That node becomes the coordinator for the write. The coordinator hands off the request to a service called StorageProxy, which figures out which replica nodes are responsible for storing that particular piece of data. It then forwards a RowMutation message to those replicas.
Now, the coordinator doesn’t wait around for everyone. It only waits for responses from enough replicas to satisfy the write ConsistencyLevel set by the client. This is what allows Cassandra to stay available and low-latency, even when some replicas are slow or temporarily unreachable.
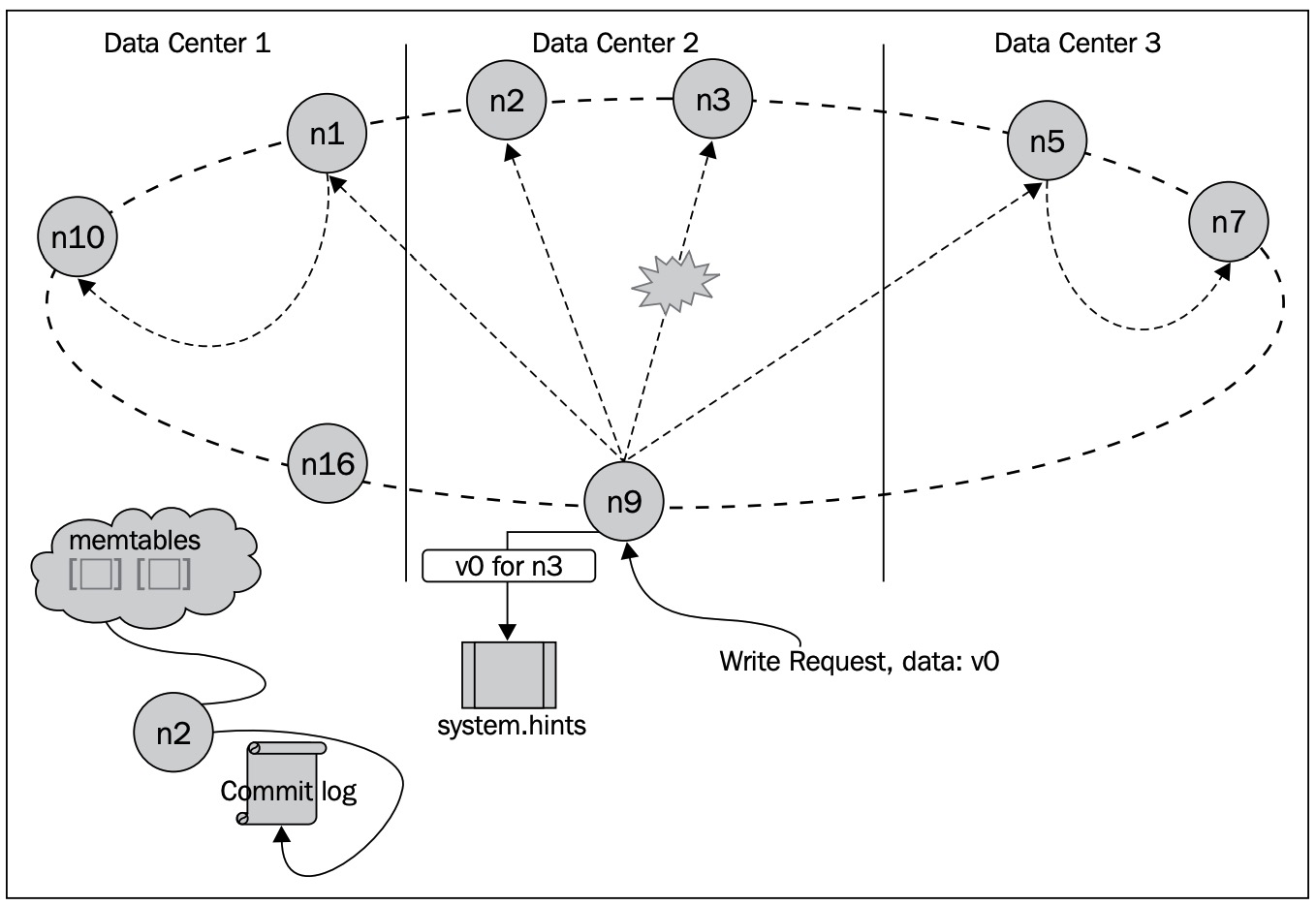
Here’s step by step flow for the write path in Cassandra:
Receiving the Write: Coordinator Node
- A client can send a write to any node in the cluster. That node becomes the coordinator for the request.
- The coordinator hashes the partition key using
Murmur3Partitionerto get a token. - This token maps to one or more replica nodes, as determined by the replication strategy (
SimpleStrategy,NetworkTopologyStrategy). - The coordinator forwards the write to all relevant replicas.
Logging for Durability: Commit Log
- Each replica first appends the write to its commit log, stored on disk.
- This ensures that the write isn’t lost in case the node crashes before flushing to disk-based storage.
- Writes to the commit log are sequential, making them very fast.
Buffering in Memory: Memtable
- Alongside the commit log, the same write is applied to an in-memory structure called a memtable.
- The memtable holds recent writes in a sorted form (usually a red-black tree).
- Each table has its own memtable, which temporarily buffers incoming writes.
- Ensuring Redundancy: Replication & Consistency
- The coordinator sends the write to all replicas responsible for that partition.
- It then waits for a configurable number of acknowledgments based on the consistency level:
ONE: any one replica responds.QUORUM: a majority respond.ALL: all replicas respond.
- This tunable consistency helps balance availability and latency.
- Flushing to Disk: SSTable Generation
- When the memtable grows beyond a threshold, it is flushed to disk as an immutable SSTable (Sorted String Table).
- SSTables are never updated once written. They’re sorted and designed for fast lookups.
- These files become the persistent, queryable storage.
Cleaning Up: Compaction
- Over time, multiple SSTables may contain duplicates, tombstones, or old data.
- Cassandra runs compaction in the background to:
- Merge overlapping SSTables.
- Discard deleted data.
- Reduce read amplification and reclaim disk space.
The Read Path in Action
Reads in Cassandra are a bit more involved than writes. Because SSTables are immutable and data lives across multiple storage layers and replicas, a read operation needs to stitch together a consistent view while staying fast and fault-tolerant.
Similar to a write case, when StorageProxy of the node that a client is connected to gets the request, it gets a list of nodes containing this key based on Replication Strategy. StorageProxy then sorts the nodes based on their proximity to itself. The proximity is determined by the Snitch function that is set up for this cluster.
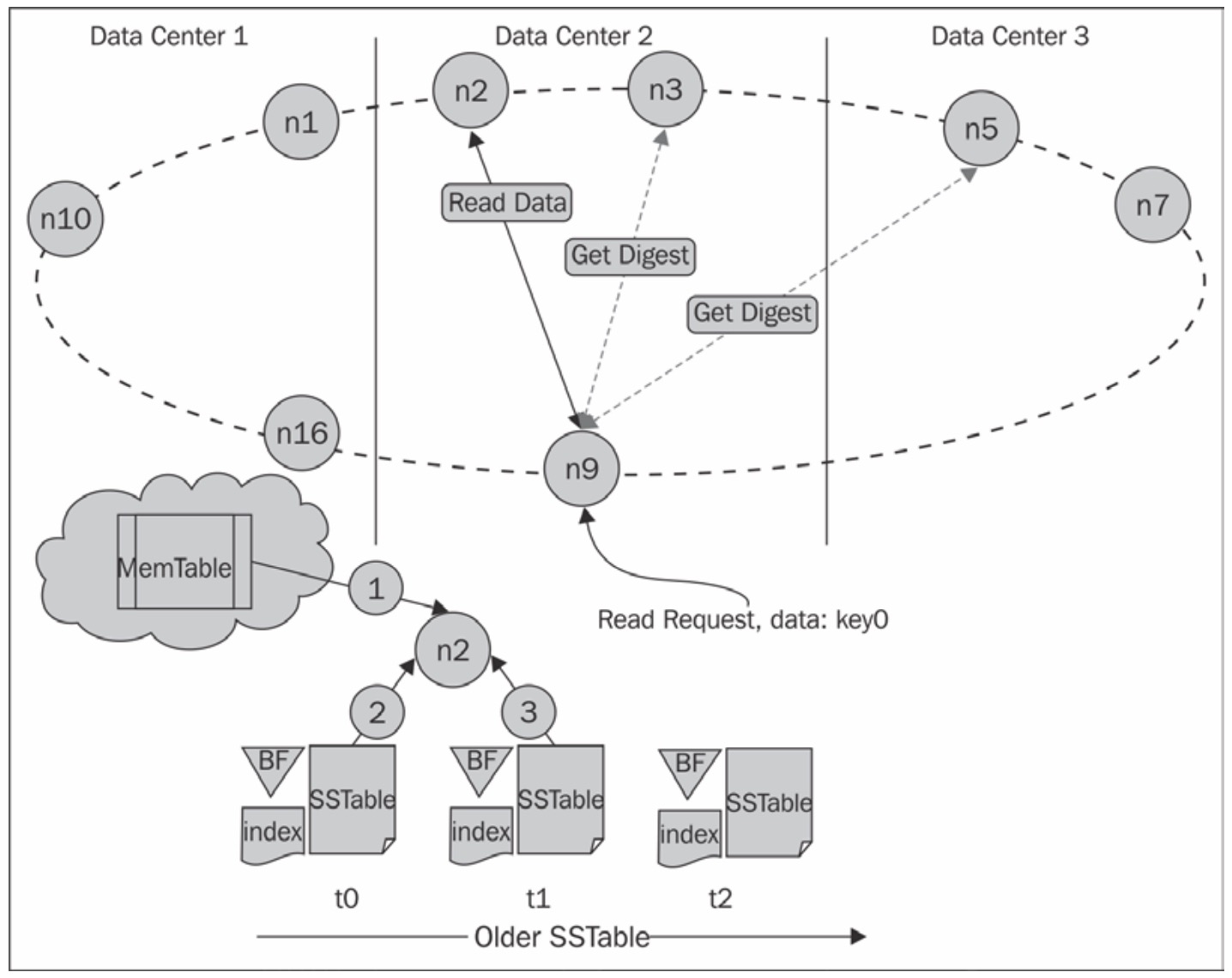
Here’s step by step flow for the read path in Cassandra:
Identify Responsible Replicas via Coordinator Node
- When a read request comes in, it lands on any node. This becomes the coordinator.
- The coordinator determines which replicas are responsible for the requested partition key and forwards the read request to just enough replicas based on the required Consistency Level.
Perform Read Repair (if Enabled)
- Cassandra has built-in mechanisms to detect and heal inconsistencies during reads.
- Blocking read repair: On stricter consistency levels, the coordinator waits for responses from all replicas and repairs mismatched data before replying to the client.
- Background read repair: On eventual consistency reads, the coordinator replies early and repairs inconsistencies in the background.
- This ensures that stale replicas catch up over time.
Fetch Data from Memtable and SSTables
Each replica receiving the request performs a layered lookup:
- First, it checks the memtable for recent writes.
- Then, it uses Bloom filters to skip irrelevant SSTables.
- For matching SSTables, it uses the partition index to directly seek to the relevant data on disk.
Since the same partition might be spread across multiple
SSTablesand thememtable, Cassandra has to merge these views.
Merge Rows and Respect Tombstones
- Each cell (column) is timestamped. Cassandra merges all versions by picking the latest timestamp across SSTables and
memtable. - If some data was deleted, it’s marked with a tombstone, which is retained for a configured grace period.
- This ensures deletions are respected even if some replicas haven’t seen them yet—preventing deleted data from resurfacing.
- Each cell (column) is timestamped. Cassandra merges all versions by picking the latest timestamp across SSTables and
Use Digest Requests for Fast Consistency Checks
- To detect inconsistencies without transferring full rows, the coordinator first sends digest requests—each replica replies with a hash of the data.
- If all digests match, good to go.
- If not, the coordinator requests full data from all replicas and triggers a repair.
Speed It Up with Caching
- Cassandra optionally uses two caches:
- Key Cache: Speeds up SSTable lookups by caching partition key offsets.
- Row Cache (optional): Stores entire rows for quick retrieval (but uses more memory).
- Both help reduce disk reads, especially for hot partitions.
- Cassandra optionally uses two caches:
Wrap Up
By now, we’ve peeked under the hood of Cassandra’s read and write paths, how data flows in and out of a node, hops across replicas, and stays consistent despite the chaos of distribution. Whether it’s write-time coordination, merging reads across SSTables, or quietly fixing stale data with digest repairs, Cassandra ensures that things work smoothly without yelling about it.
These flows aren’t just mechanisms, they’re a careful choreography tuned for scale, fault tolerance, and speed.
I hope you have enjoyed learning the internal details and flows. Stay tuned for the upcoming wite-ups.
Stay healthy, stay blessed!